Whilst running a recent training course I was surprised to find some reasonably experienced delegates were not aware of layering multiple Preceding Loads. Time, therefore, for another Back To Basics post.
Introduction
This series of posts looks at some of the features rarely blogged about as they are so second nature to many experienced QlikView bloggers. The sort of features I will use on a daily basis without thinking about it. These techniques are useful to revisit though and for anyone who has not come across these features before they are the things you really should become aware of. Preceding Loads deserve to be added to the list of features covered here.
What Is A Preceding Load?
As the name suggests, the preceding load happens in front of another load. You have probably used one already – even if you were not aware of it. When loading from an ODBC or OLEDB data source you have a SQL SELECT statement and the wizard will (optionally) add a LOAD section ahead of the SELECT. This is a basic preceding load. I would recommend that you always use one of these ahead of a database load – as it opens up a whole range of syntax that is not available in the SQL statement. So, if that is a simple preceding load, what can you do with a more complex one?
Potential Confusion
Before we get stuck into preceding loads fully it is important to understand the order things happen in your load script. In the main, script is executed from top to bottom, then let to right along the tabs (the tabs have no functional relevance are only there to tidy code). Loops and subroutines will alter this execution path, by design, but apart from that this statement holds true. The gotcha however is with LOAD blocks, which can be stacked together and execute from the bottom up. Picture the simple SQL preceding load:

The SQL part is executed and returned first and is then parsed by the LOAD statement above. This idea of loading from the bottom up holds true as we get into multiple layers of preceding loads, and it is important to keep in mind as we continue.
Why Use A Preceding Load?
Put simply, a preceding load allows you to use values derived in one part of the load in the one above it. To give a simple example, let’s say we are loading two dates from a text file and we want to know how far apart those days are. We need to convert those dates from the text values to numeric ones we can do arithmetic on and only then can we do the difference calculation. Without a preceding load the code will look like this:

You will notice that there is code duplication as we convert both of the dates twice. Whilst I have been very reliably informed (by Henric Cronström) that QlikView with it’s clever caching will not need to calculate the values twice, duplication is a bad thing from a code maintainability point of view.
With a simple preceding load we can remove that duplication and make the code cleaner and more readable. It will then look like this:
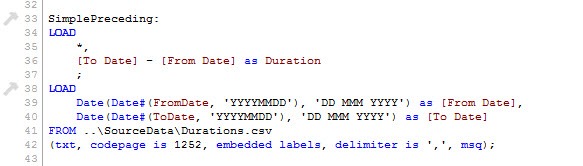
You will note that the fields we created in the lower part of the load are then used in the one above.
Also of note here is the asterisk in the preceding load. This is required to pull the fields up from the load below up to what is actually loaded. There are two potential problems you may face here. First if you omit the * then the two date fields will not be in the final data model. The other potential problem is that you can duplicate a field by having a field name used in the succeeding load that is pulled through with a * that is then used again in the preceding load. These can be hard to spot and the error message from QlikView (field names must be unique) does not always point you to the right part of the load script – so be careful.
Generally I would advise against the use of an asterisk (particularly when pulling fields from a database) but in preceding loads they are most useful. Be aware you can also pull fields up explicitly by listing them if you want to take only some fields from your lower LOAD to the preceding one.
Onwards And Upwards
And you don’t need to stop there. If you wanted to have another value calculated on fields derived in your preceding load you can add a preceding load on your preceding load. To take the example of our date interval we could then add another field based on whether a threshold has been breached or not.
Simply stack another load on top of the one before, like this:

There is no limit to the number of levels of load you can have. And whilst it may sound like you are creating a potential confusion, like a BI version of Inception, preceding loads tend to help you to clean and simplify script. You can have expressions that use fields from any of the levels below to create new values.
Advanced Features
Whilst it doesn’t really belong in a back to basics post, I should mention that there are functions you can use in your preceding loads that you may previously have only associated with the first level of load. WHERE, WHILE and GROUP BY are all permissible using values from the load before. You should probably not use these features often, but it is with knowing they are there.
Conclusion
Having preceding loads in your kit bag of QlikView load script code allows you to build complex expressions, whilst keeping your code simple by breaking things up into bite sized chunks. Duplication can be removed and maintainability can be improved. Not bad for a simple little technique.
This is the sixth post in the Back To Basics series. Look out for the next post in the series soon. If you have a suggestion on a topic please let me know in the comments field below.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Hi Steve,
I would like to share a personal experience using preceding load. With this technique I could help a customer developer to optimize a script from a chain of several “load from resident” statements to one statement with several nested load.
Well, it´s worth to say that time dropped from minutes to seconds, memory consumption was reduced during the script execution , and customer developer became happy learning how to build an optimized script.
Best Regards,
Pablo Labbe
Qlikview Consultant – ANALITIKA
Hi Pablo,
Thanks for sharing your experience here. I have had similar situations when picking up client code. If I ever see many RESIDENT statements, or worse still LEFT KEEP, I will always look to optimise – Preceding Load is often a good feature to use here.
I should have mentioned two gotchas with Preceding Load though, first is that you can’t use it on a wildcard load (FROM MyData_*.csv) or on top of a CROSSTABLE statement. Here you need to use a loop around a FileList statement rather than a wildcard and a RESIDENT load from a temporary table respectively.
Steve
Thanks Steve,
Like your example a proceding load is very good at creating a common field in the first load section which is re-used in the top. A good example is the classic ‘Calendar’ table (which you know I love!!)…
Original_Calendar:
Load
RowNo() as [%CalendarRow (#)]
,%KeyDate as %KeyDate
,Date(%KeyDate ) as Date
,num(WeekDay(%KeyDate )) as [Week Day (#)]
,Week(%KeyDate ) as Week
,num(Month(%KeyDate )) as [Month (#)]
,ceil(Month(%KeyDate )/3) as [Quarter (#)]
,Year(%KeyDate ) as Year
// Dual fields are used to display text whilst retaining the interger for sorting
,dual(WeekDay(%KeyDate ),num(WeekDay(%KeyDate ))) as [Week Day]
,dual(‘Q’ & ceil(Month(%KeyDate )/3),ceil(Month(%KeyDate )/3)) as Quarter
,dual(Month(%KeyDate ),num(Month(%KeyDate ))) as Month
,dual(Text(Date(%KeyDate ,’MMM-YYYY’)),monthstart(Date(%KeyDate))) as [Month Year]
;
Load
$(vCalendar_Start_Date) + IterNo() as %KeyDate
AutoGenerate 1
While IterNo() <= $(vCalendar_Number_Days_Between_Dates);
Here %KeyDate is reused and by using the preceding load technique the whole script is so much easier to understand when reading back at a later date…
Great post, cheers.
Richard
Hi Richard,
The same technique of converting and tidying your date ahead of doing all the various breakdowns of the date could use a Preceding Load also, just no need to use separate calendar table (unless you want to ;-) ).
I like the use of the WHILE IterNo() in that calendar script. It is even more impressive when done on a higher Preceding Load – I’ve used this to good effect where the initial load works out a range of days then a WHILE on the Preceding Load creates a row for each date in the range.
Steve
Really a vital info.thanx
I love preceding load. It makes it so much easier to write readable code as well as being far faster. I wonder what the record is for the number of precedings in a commercial system is?!
Hi Jane – I think my biggest number may be for a client I am visiting on Tuesday next week. I will have to tot them up and report back. Suffice to say though – it’s quite a few. :)
I’m an SQL developer and I’m taking my first steps in QlikView. Consequently, I’m still in the habit of thinking in terms of SQL. It looks to me like a Preceding Load is the QV equivalent of an SQL subquery. Would I be correct or are there important differences?
It is very much like a sub-query, except you are not able to specify a JOIN to the rest of the statement. The first part of the load (or the SQL load) is like the bracketed part of the SQL statement and then the preceding load is like the main SELECT block. Also, like a Sub Query, you can nest these to many levels and have different aggregations at different levels – should you need.
Steve
Thanks Steve – that’s really useful and I’ve a fair bit of reloaded script to review now, though I’m glad I read all the comments too as I also make use of a wildcard load and CROSSTABLE
Thanks Andrew. You should always read the comments! Steve.
Hi, just a question:
if there are N preceding load, I suppose that each single record is executed N+1 times: one for each preceding load and one for the “top” load. If it is true, what is the difference, in terms of performance, with N+1 Load … resident blocks ? Perhaps in preceding load the first record is executed N+1 times from bottom to top level and then next record is executed in the same manner, while in load..resident all table records are executed together for each load..resident block?
Thank you very much
Hi Stafano,
I’m not sure of quite how things work under the bonnet, but the point is that things are not executed many times, depending on the number of preceding loads. When you do a RESIDENT everything is parsed again and will take a substantial amount of time. This is not the case with RESIDENT.
Try these two bits of script and you will see straight away that the preceding load happens in about the same time as the initial load using the RESIDENT method. The second pass of the RESIDENT takes as long again:
LOAD
A,
A * 2 as B
;
LOAD
RowNo() as A
AUTOGENERATE(1000000);
Versus…
Temp:
LOAD
RowNo() as A
AUTOGENERATE(1000000);
Res:
LOAD
A,
A * 2 as B
RESIDENT Temp;
DROP TABLE Temp;
Preceding loads are great.
I use them more than sliced bread.
A few users have posted that preceding load is faster than multiple resident loads. I have actually thought the opposite; ie multiple resident loads were much faster than preceding loads. I’d assume it all depends on the types of calculations and volumes of data, but in my case using resident loads instead of preceding decrease the script run time by about 60% (~11 million records, with about 5 preceding loads, fairly complex expressions).
We have the luxury of a Data Warehouse (SQL Server 2014), hence we abstract our Dims and Facts in the DW, then load (nightly) to QVD’s, thus loading into the QVW’s for us is very simple .
Any really complex business rules are maintained in the DW abstraction layer.
Hence for example a QVD loader script will be a “select * from factInventoryLevels where ”
We plan to bring ESB into play over the next 6 months which means we can load anything in the enterprise to the DW to be consumed by QlikView.
This methodology of abstraction follows Kymbles recommendations.
Hi Paul – I always say that you should move the logic to the place that is best placed to handle it. Often getting the database to crunch data is the best place. The only exception I would put to that is JOINs where sending data that has been joined back from the database will result in a massive increase in the volume of data sent over the pipe. ApplyMap in QlikView is generally the best approach then.
Personally I wouldn’t use * even if I wanted all fields – I would generate a list of the fields to use in the select – so that it is then possible to remove fields and new fields will not find their way into the model without permission (a synthetic key could be created without the developer doing anything).
A well designed and implemented warehouse is a great asset though.
Actually I should add that Preceding Loads are faster than Resident loads, I just tested this today.
Goal: Extract a small subset of data from a very large QVD
1: Using a resident load to a QVW from a 560Mil row QVD where I want to predicate the load
with a Where clause, in fact did not complete, I got bored waiting past 2 Hours.
2: Used the preceding load using the same predicate, the load took 38Minutes, which is acceptable
for “In the dark” sorry Steve no pun intended, QVW loads.
Hi (again) Paul – yes, RESIDENT loads are generally a big cause of slow downs in load scripts. Optimised QVD loads are pretty much as quick as you can get. Over that volume of data you really need to ensure it is optimised (it will tell you if it is, nothing is mentioned of it if it is not). If your load is not currently optimised you will be able to knock the load down from 38 minutes considerably if you move it over. See https://www.quickintelligence.co.uk/qlikview-optimised-qvd-loads/ for details.
Hi Steve
I have found that optimised loads are not optimised the minute you try to involve a predicate in the LOAD. Previously I was doing a optimised load i.e LOAD * from xxx.qvd (560Mil rows). The optimised load on its own is only minutes to execute.
And then attempting to load the subset using a predicate from resident, this is what took hours to run, and this is on a big server.
Then testing the Preceding load method and got it to 38 mins. I see in your reply above there is a
“See for details” then no link?
If I can get this load time down that would be a win win.
Thanks
Paul
Hi Paul – I have updated the comment above to include the link. You will need to remove the preceding load, and any other manipulation of the data coming from the QVD. To do this you will need to do all calculations when you create the QVD – rather than when you load from it. The WHERE statement also has to be a WHERE EXISTS rather than a straight WHERE.
Anyway, the link above should work for you now.
Thanks Steve for the advice :)
Hi Steve,
as always, a very useful post. Is it possible to use preceding loads over multiple tables?
I’ve used preceding loads throughout my script and would now like to use two of these derived fields to create a further derived field. I can’t get my head round the order I’d need these in. Is this possible?
thanks
John
Hi John – are these tables being concatenated on load, or associated in the data model? If it is the latter then you will need to do a separate preceding load on each. If they are concatenated then you can put the same preceding load on each table. Make sure you don’t use a preceding load with a wildcard though – as things will break. It is possible to concatenate the base data and then do the preceding load on a load resident of the concatenated data – but this is generally less efficient in the load script.
They are being associated rather than concatenated. Lets say there is an Order table and a Shipping table, the Shipping table has your ‘Over ten days’ as preceding load. The Order table has a preceding load generating ‘Important Customer’ based on a couple of fields, value and number of orders etc etc.
I’d like to then use the values of ‘Over ten days’ and ‘Important Customer’ to create a new derived field called ‘KPI’
You will need to get the value from one table into the other table, ahead of the preceding load. I would suggest, in the example you give, loading the Order table first and storing to QVD. You can then create a MAPPING LOAD from that QVD, to ApplyMap onto the Shipping table, giving the Important Customer information where you need it. Once it is all in the same place you can blend the data. You can benchmark whether loading from RESIDENT before dropping Orders is quicker than loading from QVD – it seems to depend on the data as to which way is best.
Hi,
I would like to thank you for this topic.
I’ve a question, in fact I have a problem loading my data.
I wish to create a calculated field from both tables.
I selected my tables, but I have an error like: Failed to read OLEDB and join. here is my code:
DIM_DOCUMENTS :
LOAD Month (“DOC_DATE”) as Mois,
Year (“DOC_DATE”) as Année,
date (“DOC_DATE”) as Date,
“DOC_TYPE”,
“DOC_STYPE”,
If(DOC_TYPE = ‘A’, ‘Achat’, if(DOC_TYPE = ‘V’, ‘Ventes’)) as Type_de_doc,
/*Sous types de documents*/
If(DOC_TYPE = ‘V’,
if(DOC_STYPE = ‘P’, ‘Pro-forma’,
if(DOC_STYPE = ‘D’, ‘Devis’,
if(DOC_STYPE = ‘C’, ‘Commandes’,
if(DOC_STYPE = ‘B’, ‘Bons de Livraison’,
if(DOC_STYPE = ‘R’, ‘Bons de Retour’,
if(DOC_STYPE = ‘F’, ‘Factures’,
if(DOC_STYPE = ‘1’, ‘Factures Financières’,
if(DOC_STYPE = ‘A’, ‘Avoirs’,
if(DOC_STYPE = ‘0’, ‘Avoirs Financiers’,
))))))))),
if(DOC_TYPE = ‘A’,
if(DOC_STYPE = ‘D’, ‘Demandes de Prix’,
if(DOC_STYPE = ‘C’, ‘Commandes’,
if(DOC_STYPE = ‘B’, ‘Bons de Réceptions’,
if(DOC_STYPE = ‘R’, ‘Bons de Retour’,
if(DOC_STYPE = ‘F’, ‘Factures’,
if(DOC_STYPE = ‘1’, ‘Factures Financières’,
if(DOC_STYPE = ‘A’, ‘Avoirs’,
if(DOC_STYPE = ‘0’, ‘Avoirs Financiers’)
))))))))
) as Sous_Type_de_doc,
“DEP_CODE”,
“DEV_CODE”,
“DEV_CODE”,
“DIV_CODE”,
“DOC_DT_PRV”,
“DOC_EN_TTC”,
“DOC_ETAT”,
“DOC_NUMERO”,
“DOC_PIECE”,
“DOC_TX_DEV”,
“DOC_TXRFAC”,
“NAT_CODE”,
“PAY_CODE”,
“PCF_CODE”,
“PCF_PAYEUR”,
“PCF_REMMIN”,
“PCF_REMVAL”,
“PRJ_CODE”,
“REG_CODE”,
“REP_CODE”,
“SAL_CODE”,
“SRV_CODE”,
“TAR_CODE”;
SQL SELECT “DOC_DATE”,
“DEP_CODE”,
“DEV_CODE”,
“DIV_CODE”,
“DOC_DT_PRV”,
“DOC_EN_TTC”,
“DOC_ETAT”,
“DOC_NUMERO”,
“DOC_PIECE”,
Type_de_doc,
Sous_Type_de_doc,
“DOC_STYPE”,
“DOC_TX_DEV”,
“DOC_TXRFAC”,
“DOC_TYPE”,
“NAT_CODE”,
“PAY_CODE”,
“PCF_CODE”,
“PCF_PAYEUR”,
“PCF_REMMIN”,
“PCF_REMVAL”,
“PRJ_CODE”,
“REG_CODE”,
“REP_CODE”,
“SAL_CODE”,
“SRV_CODE”,
“TAR_CODE”
FROM ICP.dbo.DOCUMENTS;
Join (DIM_DOCUMENTS)
Load “DOC_NUMERO”,
“LIG_QTE”
From ICP.dbo.LIGNES;
Inner Join
LOAD *,
If(Match(DOC_STYPE ,’A’, ‘0’, ‘R’),-(LIG_QTE),LIG_QTE) as ‘Qte’,
If(Match(DOC_STYPE ,’A’, ‘0’, ‘R’),-(LIG_QTE * L.LIG_POIDSN),(LIG_QTE * L.LIG_POIDSN)) as ‘Poids’,
If(Match(DOC_STYPE ,’A’, ‘0’, ‘R’),-(LIG_FRAIS * LIG_QTE),LIG_FRAIS * LIG_QTE) as ‘Frais1’
Resident DIM_DOCUMENTS, LIGNES;
Hi – make sure you are not mixing SQL and QlikView syntax for joins in the wrong places. Separate out and test each of the parts separately to check they work before performing joins. I think the issue may be this chunk of code:
Load “DOC_NUMERO”,
“LIG_QTE”
From ICP.dbo.LIGNES;
You are using a LOAD statement to try and pull from a SQL Table, and it should be written like this:
LOAD
“DOC_NUMERO”,
“LIG_QTE”
;
SQL SELECT
“DOC_NUMERO”,
“LIG_QTE”
From ICP.dbo.LIGNES;
The LOAD part is not strictly required – but I always include it as it makes it clear what is happening where.
Hi Steve,
another really useful article!
I think from reading above, I kinda already know the answer to this question so should be quick response!!
I’m connecting to SQL database and for example will be pulling in about 20 fields from a table which has about 100 fields, and 110,000 rows of data so far (growing daily). In testing in my script I have used * in SQL Select, example1:
WorkRequests:
LOAD “field_1”,
“field_2”,
“field_3”,
“field_4”,
etc;
SQL SELECT *
FROM “archibus_live”.afm.wr;
BUT… Would I be best changing this to the following script, example2:
WorkRequests:
LOAD “field_1”,
“field_2”,
“field_3”,
“field_4”,
etc;
SQL SELECT
“field_1”,
“field_2”,
“field_3”,
“field_4”,
Etc;
FROM “archibus_live”.afm.wr;
In the preceding load section I’m doing all my Apply Mapping and reformating of date fields etc, and then storing the these into QVD files for later use in the dashboard apps! So the qvw I’m working on here is my loader file.
So to recap: My script(s) is currently based on example1, should I go with the script based on example2?
Thanks
Dan
Definitely! If not all fields are sent over the network to just be ignored by QlikView.
Hello Sir,
Again a very useful post. Something which I was searching for long. Very neatly described. But I have some questions here.
1. In the entire blog you are telling that RESIDENT LOAD is slower than PRECEDING LOAD. Its true. But I would like to know in detail why is RESIDENT LOAD is slower? What’s happening behind the scene?
2. Two limitations you told are Wildcard Load and CROSSTABLE Load. Here you are telling that “we need to use a loop around a FileList statement rather than a wildcard”. How to use FileList statement ? Can you explain with an example data and .qvw application?
Hi Joydip,
I’m not familiar with all of the inner workings of QlikView. All I know is when you do a Preceding load the data is just parsed once, with all preceding layers proceeded in one pass. With a resident the data is parsed a second time – this will always be slower.
FileList syntax is like this:
for each vFile in FileList(‘..\MyFolder\*.qvd’)
Data:
LOAD
*
FROM [$(vFile)] (qvd);
next
There are a number of advantages to this over doing a wildcard load, including the ability to embed logic within the loop. The fact you can also do Preceding loads without the concatenation going wrong is also a big plus.
Thank you Steve for your quick reply with all the explanation. Every time I just love to hear from you. I got your point clearly. But tell me one thing, in the FileList syntax what should I store in the variable vFile? Is loading data using FileList function much faster than Wildcard load?
vFile is populated from the FileList function, for each file that exists with the specified mask the name of that file is put into the variable. Take a look at it in debug to see what is happening.
FileList is no slower than using wildcard load, but I doubt it is faster either. It is much more robust and flexible though – and that makes it my method of choice for enumerating files.
Thanks Steve. Let me try this thing. If I’m not able to do it I’ll surely come back to you.
Steve,
I have a large SQL stored procedure that I need to transfer into Qlikview. The stored proc has many temp tables, but I only want the final results to be loaded into qlikview as fields. Would preceding loads be the way to go to bypass the need for many temp tables, or is there a different approach I should be using?
Thanks!
Hi Marshall,
Getting data from stored procedures is never ideal, as you don’t have control over what data you pull within a WHERE statement or by picking only certain columns. If you can load the tables that feed into the stored procedure separately and then glue them back together in QlikView that would be advantageous from a performance point of view, but it may not be possible (depending on your data). Another approach would be to run the stored procedure into a staging table in SQL and point QlikView to that, this way you could potentially put a over that table.
Good luck!
Steve
Thanks for the quick response Steve!
Your latter suggestion is actually what our IT director suggested when we first started brain storming this project, and he isn’t even that familiar with Qlik! So I’ll probably stick to that as I was really struggling to produce the tables separately and glue them back together since they call/build on each other a lot in the original SQL stored proc.
Appreciate the advice and insight!
thank you, that’s helpful!
hi
can you look the preceding load
LOAD CategoryID,
ProductID,
ProductName,
QuantityPerUnit,
SupplierID,
UnitCost,
UnitPrice,
UnitsInStock,
UnitsOnOrder;
SQL SELECT *
FROM Products;
LOAD Discount,
LineNo,
OrderID,
ProductID,
Quantity,
UnitPrice,
OrderID&’_’&LineNo AS OrderLineNo,
UnitPrice*Quantity*(1-Discount) AS LineSalesAmount,
APPLYMAP(‘MAP_Unit’,ProductID,0)*Quantity AS CostOfGoodsSold;
SQL SELECT *
FROM `Order Details`;
The code itself looks fine – what is the issue you are facing?