Everyone has their way of creating a QlikView calendar script. Here, however, I argue you should ditch that script and do something different.
The Traditional Calendar
Ever since my initial QlikView training I have frequently seen examples of calendar scripts and how to build them. Torben Seebach’s recent Community post being a great example of how you can super charge your calendar create script. Long ruminations on how to obtain the min and max values over a large data set have largely been driven by setting the variables ready to enumerate for a calendar script (though this is not the only reason you may want to get a min and max value out of a table).
Given all that, it may surprise you to learn that I very seldom use a calendar script in my QlikView code.

The Inefficient Calendar
Calendar tables are useful for splitting out a single date into all the myriad of ways that date can be categorised; it’s year, month, quarter, day etc. etc.. I’ve seen some calendar tables with many many fields in them. Herein lies my first problem with calendar tables; I always advise keeping the number of fields in your data model to a minimum to avoid confusion and clutter. A pre-canned calendar script with many dimensions encourages developers to have more fields than than they actually need. Another thing I try to keep to a minimum is joins in the data model. Whilst these are not generally a problem, there is a slight overhead in each hop that need to be made to pull all data together for an expression. As date fields are common dimensions expressions involving them, in a linked calendar, over large data sets will start to perform less well. Finally, no matter how well you optimise the script, there is an overhead to building your load script each time you reload your front end application.
The Alternative Calendar
What I tend to do as an alternative to the calendar table is to build my date dimensions in the fact tables themselves. The code to split a date into it’s constituent parts is the same as when done in a separate table, and if manipulation is required to derive the date (for example converting from a text value in a CSV) then this can be done in a preceding load. Yes, there is an overhead in calculating the date parts for each row, but QlikView’s expression caching should kick in here, and I’ll wager that this overhead is nothing compared to the drive\network lag of pulling your data. If you have an incremental load then the dates are not recalculated on old rows. If you have many dates in your table you can choose which fields you break out into what dimensions – based on need rather than what is in your saved script.
Most of the advantages of using a calendar script and separate table can be obtained, without the disadvantages in the section above.
In this code you can see I am deriving a few date based dimensions in among other fields:
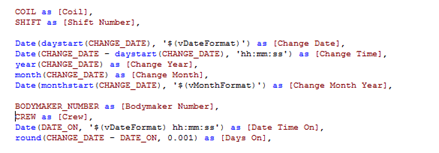
Plugging The Gaps
One of the potential disadvantages of the approach above is that you can have gaps in the date field. in many cases this is a moot point, as either there is data for every day or it doesn’t matter that there isn’t. Having a month list box with only a few months in may look strange (I tend not to worry about this though), but this can be overcome by a force concatenate of missing months (using WHERE NOT EXISTS). If a report is required where you show all days where nothing happened then the same approach may be used for days, in this case remember you can derive all your dimensions as you append the dates.
Another disadvantage, if you have incremental loads, is that it is easier to add new date dimensions to a calendar script than to stored QVDs. It is not to difficult when your dates are in-line though. If you spend new rows to an existing QVD on each load simply add the new field to the increment part of the load, and also when loading from Dave QVD – this will break the optimised load on first run but you can restore this by reverting to the saved field for subsequent runs. If you have QVDs that are not appended to you will need to create an ad-hoc QVD generator to add the new field to all stored QVDs – this is a relatively simple task.
A Further Thought
If calendar tables hanging off your fact table is what you want (perhaps performance is not an issue for you) you could generate a calendar QVD with all the date parts in for as long a period as you like. This can then be loaded with a WHERE EXISTS into the presentation document. Each field that date break downs are required for simply requires the generic fields names in the QVD to be renamed, to avoid loops and synthetic keys. This way the min and max deriving and the loop is not required and your front end load is simply optimised loads from a number of QVDs – which is clean and tidy.
Discuss
This is a topic that I am very keen to hear other people’s thoughts on, particularly those who know details of QlikView’s inner workings. There are people I know of who are QlikView architecture experts who use calendars, so perhaps I am on the wrong tack here? What I do know is that fewer tables can perform better and calculating date dimensions in-line does not adversely affect data loads.
Please discuss below, I am ready to be challenged on this.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Well i am myself one of those guys that doesn’t use calendar qvs, mostly because I as you don’t want all those never used fields (I must say that seebach’s calendar script is rather clean compared to a lot of other examples I’ve seen at customer and around the community).
I seldom use max/min as I prefere hardcoded values instead (mostly because I want to control the number of values in the year field – always funny when something goes wrong in the back end / db and the qv app has created a calendar with all dates 1900 to 2100 :).
I have not thought about the performance factor though but I am interesting to hear / investigate the impact. It might be that calendar tables are a form of do not count( distinct) light…
Will do some testing tomorrow.
Thanks Johan. I agree on the rogue years, it’s one thing showing 2041 as a year in a list box where there is duff data, showing every year up to and including 2041 is something else completely!
Hi Steve.
Do you feel that Calendar is something different from any other dimension in that sense?
I mean if we have simple `Star scheme` model with Sales transaction as fact table and Customer, InventTable and Calendar as dimensions – we can in script left join all dimensions to fact table and have a `Single Table` model.
So from my point of view it is a `Star scheme` versus `Single Table` scheme question.
Hi Vadim. Not at all, whether its the calendar or any other data, fewer fields and fewer associations will perform better. In each case though there are a number of factors to consider. Different granularity in the tables mean that joins are not possible. A logical data structure may aid developers understanding where a single table may confuse. However, dates and simple ID/Name lookups I would always keep in the one table. As I assert in another post; ApplyMap is my favourite QlikView statement.
Customer and Inventory tables do seem sensible to have in separate tables though – if there are more values in those tables than just customer name and product name.
So if that is most frequently `Star` scheme vs `Single table` scheme question then we may look at usual arguments for `Star` scheme. I commonly meet assertions that while `Single table` scheme performs better on some dataset, `Star` scheme consume less memory and consequently on bigger datasets can perform better.
Tangentially I most frequently implement asOfDate variation of Calendar, similar to Calendar described by Richard Pearce at http://community.qlik.com/docs/DOC-6593. Not only it make `Point in time` analysis less complex, but it also make achievable comparison between various periods with time dimension on chart.
That is frequently a requirement in our projects and AFAIK it cannot be implemented by lookup style calendar or calendar embedded into fact table.
You would be able to use point in time indicators, provided you were refreshing the whole data set – it would not work with incremental loads. There is always the option of writing set analysis against date fields (or date parts) rather than relying on a IsInCurrentYear flag – but I agree flags do make the syntax of these expressions simpler.
>> but I agree flags do make the syntax of these expressions simpler.
Not only so. I believe set analysis would not help with problems like that: “How to trend Current Sales vs Prev Sales, using date as dimension?” https://community.qlik.com/t5/QlikView-App-Dev/How-to-trend-Current-Sales-vs-Prev-Sales-using-date-as-dimension/td-p/587947
Hi Vadim,
That technique of having a one to many association to another table to allow comparative analysis is something I covered in a previous blog post () and is a perfect example of why you would have a separate table. My example shows accumulations and moving annual totals – but it uses the same idea. I hadn’t thought of having a whole offset calendar associated – that opens a lot of doors for period comparisons – thanks for sharing the link.
Also I would recommend document by Richard Pearce – [Archived] for example of such approach
My addition to the discussion is to consider the in-memory data size. While adding a few new fields to a fact table is not much of an issue for a small fact table, for a very large fact table, every additional field will make a large impact on the size of the underlying data table. Adding one key value, especially if autonumbered, has a much lower impact on the data table size.
Regards,
Stephen
Would that be the case if the field was created in the fact table in the QlikView load script and only stored in QVD? Obviously if it was created in the source data, or saved to CSV then it would be a disaster – but I would have thought the compression algorithms would sort everything out otherwise?
I am talking about the data model in your final QVW, not anything to do with CSV.
Just an example, if I load an Order table with about 30,000 rows with the calendar fields (11 fields) built in, the in-memory database size is about 830Mb. If I split out the calendar into a separate table using my standard calendar load (and using AutoNumber on the DateID) then the total database size will go down to about 660Mb. The large difference in size is the Order’s data table – where the pointer indexes are stored.
As the fact table size increases, the differential between storing the calendar fields in the fact table versus in a separate dimension table will only increase. When dealing with multi-million row fact tables, it becomes more and more important to minimize the number of fields. A smaller data size = smaller user cache = better performance in a given system for more users. You may get faster performance having the fields in the fact table, but potentially for a smaller number of users.
Regards,
Stephen
Unfortunately the environment or audience will determine which route is chosen, i have recently only started with QV and have in my short time already experienced that in my world, people want to see all days and want in their format, so i have no real opinion but to say that the user normally gets what the user wants.
Needing all days to be pickable when there are days without data is a good reason to go for an external calendar. Many data sets will always have something happening on each day though.
Steve,
As a newbie to QV, I’m not sure what you mean by “but this can be overcome by a force concatenate of missing months (using WHERE NOT EXISTS). ” … as well as “This can then be loaded with a WHERE EXISTS into the presentation document”
– Do you have a few examples?
Jarrell
When loading you can use a CONCATENATE prefix on the load. This will add the new data to the existing table. By adding extra dates to the same table you can ensure all dates are covered. With WHERE NOT EXISTS you can then only add dates which were previously there – reducing redundant rows. You will find information on both techniques if you search online.
Hi Steve,
An interesting post and discussion.
My take on this is that I value readable, consistent and predictable scripts and data models and that productivity is important to me (I’m lazy, don’t like having to do the same thing twice). Because of this, I use my standard calendar subroutine which creates a calendar table with a minimal amount of fields. If needed, this subroutine supports easily -extending- the calendar with additional fields. With this approach, cluttering the data model is not going to happen.
Besides being easy to read (it’s a single call to a subroutine) it is also very productive, as it requires no scripting (I’ve already done all that work, once) and also automatically creates all the relevant Set Analysis expressions. I don’t have to think about writing “Year to date”, “This month last year”, “Rolling X months” Set expressions because those are already there ready for use (but can be easily disabled if not needed).
Adding just the specific date dimensions to the fact table requires writing additional, customized script every time. This is requires more effort (and is therefore less productive) and probably harder to read and maintain. I’m not saying I wouldn’t use it, but it’s not a route I would go down unless I had an indication that the usual way won’t be cutting it. As Donald Knuth puts it: “Premature optimization is the root of all evil”.
@Johan, if something goes wrong in the back-end you would want to show this in QlikView. That is the best way to get data quality issues resolved. As I believe data quality is a responsibility of the business (who are the owners of the data), I follow a “monitor, report but don’t correct” (unless specifically requested to do so) approach in my projects and applications.
Cheers,
Barry
Hi Barry
I agree with what you said. Could you post an example of what you use? I don’t like to clutter my model.
Hi Barry,
Many thanks for your thoughts – I was hoping you would wade in and comment! I wouldn’t say my route takes lots of extra coding, and it does cause me to think about what I am using or not – rather than accepting a default. I guess that is why pre-canned scripts (added by Include, Function Call or Copy/Paste) are great for the masses as it gives them one less thing to think about. Your function call does sound particularly neat with the variables it creates also – it always surprises me how many people are not aware of the Sub function in QV load scripts.
Regarding optimisation, Rob Wunderlich surprised me when he said (at your excellent Masters event) don’t spend time optimising stuff if it’s only causing a small amount of delay. From someone who I know can supercharge a QlikView app it seemed curious he would advise an “it’s good enough” approach. Thinking about it subsequently it does make perfect sense and I do try and bear it in mind (event though it doesn’t sit well with my perfectionist attitude).
On your comment re: Johan’s duff year comment, you would still see the outlier year in the list box, you just wouldn’t show values that weren’t there – which would only cause more confusion to the business. Setting a static max/min date for the calendar would actually hide the rogue value – which as you suggest would be worse. Where I have data sets I know have a lot of data quality issues I will sometimes bring those to the fore on a Validation tab – which changes colour when there is a known breach of data quality.
@Barry Steve pretty much said it, though i usally do a “full” calendar with hardcoded start and end.
I usually do a validation report / sheet to cover for the hiding of bad data. I should also say that its not neccecary bad data – a contract spanning over ten years is one example. My calendar date is mostly used for back in time and rest/next year analysis. When the user/analysis needs the dates outside this range I use another date field (with a bare minimum of add. calendar fields.
I’m also a huge fan of Robs “its good enough” when doing calendar script.
About two years ago when I switch from calendar qvs to building it from scratch all the time I saw that I spended more time commenting stuff in my calendar script then writing the whole from memory.
When using calendar script I guess its a matter of being restrictive on what fields to include in the standard model :)
Barry,
Would love to see your calendar, especially the built in set analysis.
My views are the same that I like quick easy to read scripts as multiple people end up working on the them, this then reduces development cost.
Hey,
Here’s my 2 cents (and a lot of them):
Consistency:
I strongly agree with Barry. The Time dimension must be consistent across applications, and easy to implement, not only for developers but also for super users. A good subroutine helps self-service a lot. In addition to this, then if you use a time dimension consistently, you also get to reuse your set expressions and typical drill down/cyclic groups. Reuse and consistency across applications is key to a great Qlik environment.
Configuration and Reuse:
I typically include a file in the first line of every Qlik app. This file includes Path definitions, the Calendar and default expressions. This ensures reuse and the ability to quickly do a change across a whole Qlik environment.
Holidays:
There also the scenario of holidays, these special days, need to come from a separate source. Again if this is a requirement for the client, then the standard Calendar script should handle this.
Language:
Some organisations want to display dates in multiple languages. Here a Fact based time dimension, will come short on adding all these very redundant fields.
SCD:
The Fact based time dimension is not really a option in a SCD Type 2 scenario, if you’re handling this, you just want 1 field that is your surrogate time key. Which then needs to be joined onto your fact. Joining the whole time table into your fact, would be quite silly, and does not work well with non SCD based Time sources.
Performance:
Unless you a have very specific applications, that require a single high performance fact table. I would never go with the Fact based time dimension approach.
Realtime/Partial loads/Direct Discovery:
In a scenario with frequent data updates, having the your Time Dimension in the fact (and the fact is the only updated table), produces unnecessary calculation overhead when loading data.
Filling Holes:
I think this is one of the biggest errors you could do, adding rows to your fact table, you are basically altering your source data. This should be strictly forbidden from a validation standpoint – and some companies would forbid this, I would certainly flag this if I need to production qualify an application.
All in all, I think there is a lot more advantages to a default calendar, then a custom or fact based one. Unless a you a very specific performance requirement.
But in general, I think one of the biggest errors in Qlik is that you need to create this calendar. Why on earth does Qlik not ship with Time and Date functions like all the others tools, is beyond me. Even Excel has better Time handling than Qlik.
If you’re in any way following any guide lines that Kimball outlines in the Data Warehouse Toolkit, then you would never consider a Fact based time dimensions. Its his first lesson, never to have a either computed or runtime converted Time and Date display, his reasoning is very solid, but way to long for this discussion.
Hi Torben.
Thanks very much for your comments.
One of the main points for the pro calendar definitely seems to be simplicity and ease of use – which I can totally subscribe to. You do however acknowledge that the most performant approach on a massive data set is to have every in as few tables as possible. It was in one of these scenarios where I had to optimise everything to the nth degree that I started avoiding the calendar table (partly because of the duration of the min/max which your solution avoids but also performance in the front end). From a scalability point of view I suppose I like the embedded calendar as you can never be sure when your very big data set becomes a massive data set.
The luxury of always having a blank page is not one I have, so I often inherit documents in all kinds of states. Many of these will have multiple problems in the data model. I don’t automatically strip out the calendar table in these cases – I can see they are a useful shortcut and in most cases perform fine. I do often pull out fields from these tables that have no relevance to the company using them – e.g. financial period fields that don’t even match those of the company in question!
The appending rows to the fact to fill holes in the calendar is something I will very rarely do. I don’t see it as a problem though – as any values that you could be counting or totting up will contain nulls – so no data is affected. Personally I would tell the client that the reason they are only seeing seven month fields is that there are only seven months worth of data in the table. Creating the remaining ones is actually more confusing (IMHO) but some customers insist on seeing all twelve months to make things look tidier. Where I do use the append rows, and believe it is the right approach, is on Section Access fields – so that users with no data associated with them can get into the document and see no values, rather than not being allowed into the document at all (which could be down to any number of reasons – not just missing data).
I have to concede that there are a number of scenarios where the attached calendar. generated at load time, is the best approach – what I hope this post has done is caused people to realise it is not the only approach. It’s good it has got conversation started also!
One concern letting fact tables control calendar (and other hierarchies) could be the sorting of the rows in List boxes, Tables etc.
It must be faster letting QV list rows as they appear in memory. Therefore I use Load order. Your approach will load rows in random sorting.
I prefer to load all hierarchies (including time) before fact tables, to controll sorting in memory. Also I load all hierarchy fields individually in the final app, before loading the hierarchy (joining the fields together). It takes few seconds.
Some fields, Department, Manager etc., should not be sortet alfabetical but by an Id not needed in the final app. It is possible to sort Department by DepartmentId in a listbox or graph, but I find it much better to sort by load order, disregarding those Id-fields in the app.
Hi Jerrik,
That is an interesting thought. I had not assumed that natural order would be faster, and would actively try and avoid using load order to sort values. Partly due to either having to add a SORT to the extract (which would add overhead) or trust that rows will be served up in the order you expect. I have even created dual values including the RowNo() on load in order to be able to explicitly sort in load order – rather than trusting QlikView to do as you ask it. It would be interesting to find out if anyone knows for sure that Load Order sorting is quicker than Numeric sorting.
I would have thought if you have dimensions in separate tables purely to enable Load Order sort the associating of the field in the data model would add more overhead than the sort order would save. I couldn’t say for sure though.
Agree, would be interesting, if Qlik people could comment on what is fastest – sorting by load order, sorting by values or sorting by another field value.
I do not keep dimensions in separate tables. I load them in separate tables (Store, Region, Concept etc.), then load one hierarchy table and drop the separate dimension tables. The result is a starflake schema when the fact table are loaded.
Load order is the fastest as there is no sorting necessary. The values are presented as loaded into the symbol table. You can set this by loading a small temporary table with the required order in a field, load the dimensions and/or facts, drop the temp table. The original order is retained in the symbol table.
I will need to remember this when optimising. Thanks for the definitive answer!
This is great thread. Thanks to Steve and everyone! Personally, I prefer having one standard Master Calendar table which has all the required Point-In-Time calculations with Flags. This will be one standard QVD file which gets updated from upstream systems once in a day. And then all the other QlikView applications can rely on this QVD file and while only bringing only necessary calendar fields. This works well in large QlikView enviroment where you have multiple QlikView Developers and using this approach they always have one stand Master Calendar.
Cheers,
DV
Hi Deepak,
Interesting to hear that you use the calendar in a single QVD approach. I like this from the point of view that I try and make my front end applications only load data from pre-created QVDs. The flags for Set Analysis is certainly a compelling argument for a date table that can be recreated – setting the InCurrentMonth flag to the appropriate value each time it is created.
Deepak,
I agree that If possible the calendar should be controlled from upstream. But since Qlik can generate a Calendar so fast, and field names and keys can be controlled from script, I think the script approach is more flexible and is a solid.
Steve,
I thought you meant that you prefer the denormalized approach?
Also from a dimensional modelling perspective, time must be a Dimension. And one could even go so far as to normalized it even further into 3. normal form. Which would take less space, and be slower.
Hi Torben, I always look for the best solution for the scenario I am faced with. And that was the point of the post, to make people consider the alternatives. The provocative title was to grab the attention – not because I felt this was the only approach.
Hmm, not sure I like your approach. It creates a lot of noise. I properly use the Fact based approach in 1 of 100 apps I build. Whats your count?
Remember your paragraph: “Given all that, it may surprise you to learn that I very seldom use a calendar script in my QlikView code.”
Steve, your blogs are fantastic and sure help me think about why we do things. This article has really opened my mind to some options and which way is better with the calendar table. The in memory data size on the fact table is very interesting. If this is true, where it is more efficient to use a separate smaller calendar table instead of storing this on the fact table, wouldn’t it be the same for two column dimension table’s that I normally would have used mapping table’s with?
Hi Josh.
Many thanks for your kind comment. As with anything, there are always trade off’s. Mapping values into fewer tables will generally be quicker, as fewer associations are required when QlikView calculates expressions. As Stephen describes though, more memory is required to store the values. If memory is tight more associated tables could well be better, but generally memory cost is not the bottle neck these days.
Hi Steve
At this point, I’m using a Calendar table to display data fields on application. Based on the selection, I use Set analysis to select data in fact tables. For now it’s working.
And it will continue to work! There is nothing fundamentally wrong with calendar scripts – it’s just that I tend not to use them as a matter of course. There are times they are essential though.
Great post and excellent comments. I favor the same approach — having calendar fields in fact table for one important reason which is slowly changing dimensions (SCDs). Since QlikView links any two tables with only one field, having SCDs requires also linking by date (besides IDs) which makes calendar a very special dimension, unlike others. If calendar is created as a separate table then a separate link table is required that links IDs and dates, which leads to a distorted start scheme: fact table -> link table -> dimensions and effectively doubles (from 1 to 2) number of links an expression should follow. Not only downgrades it performance, but also leads to increased memory consumption since synthetic keys need to be created from IDs and dates. These synthetic keys require order of magnitude more memory than just IDs due to higher cardinality and greater length, thus reducing possible gains from normalization.
In the case when calendar is part of the fact table it effectively serves as a link table which allows having normal star schema: (fact table + calendar) -> dimensions.
Thanks for your comments Dmitry.
Hi, Dmitry.
Thank you for interesting comment. Unfortunately I cannot understand it yet.
Could you please elaborate on that question, or give some useful link to description of your approach.
Looking at https://community.qlik.com/t5/Design/Slowly-Changing-Dimensions/ba-p/1464187 blog post as an example of slow changed dimension and dealing with it I can not grasp how joining calendar to fact table could help in that scenario,
Hi all,
nice discussion so far. I do like all three approaches and choose for the situation:
1. script created dimension
2. precreated QVD
3. fact based (eg. for concatenated multi-grain facts)
Another aspect is date dimension role-playing (multiple date dimensions or hierarchies). In this case I would probably prefer loading several calendars from a precreated QVD with different aliases.
However, IMHO it very depends on the given situation but in normal case (80%) I think option 1 will be used. And, I like the Barry’s way to having all things together in one sub.
– Ralf
Late to the discussion but I thought I’d wade in with my views.
I would always go for a separate calendar table for a number of reasons already mentioned by others above:
1) We all know a perfect star schema is often hard to achieve in QV or will take more work than the benefit in performance it will offer. But I still try to apply the theory of keeping dimensions out of my fact table(s) to come as close to a star schema as is possible.
2) As mentioned by Steve Redmond, keeping dimensions out of your fact table when using an incremental integer key between the 2 tables will result in the smallest memory footprint. Memory is so cheap and readily available in the 64bit world we now find ourselves in that the memory cost of an application is often not even considered. However when dealing with very large data sets it is still critical in my opinion. I remember the days when we were limited to a max of 2gig with 32bit windows and so I guess I’ve got the desire to be as efficient as possible with resources still ingrained in me.
3) I’m lazy and so being able to just copy and paste a calendar script is quicker and so preferable. That said the script (and thus the resulting calendar dimension table) shouldn’t include any unnecessary fields. I tend to have a huge calendar script and comment out the fields I don’t need when implementing it in an app. I can then simply uncomment a field if I find I need it later.
With all that said there are often some really bad points in some of the publish calendar scripts (including those used in the standard training). Such as the tables used to derive the min and max dates loading the same number or rows as the fact table they are derived from, all containing the same min and max values. I know it will be soon dropped once the min and max are set to variables but whilst it exists it takes up a larger memory footprint than is required. Yes there are several ways to avoid this but it amazes me how many published calendar scripts don’t contain any of the possible solutions.
Regards
Matt
Hi steve,
I have a requirement regarding dates.
assume I have a column which has date values.
Now i want to create a chart where Month should be the dimension and my chart show the chart for the previous 15 months based on the current date.
what my understanding was to load the data from the files(data is in EXCEL) and I thought reducing the dates in the load script, but I realized that it would be either static or we have press the reload or an automatic scheduling should be their.
My doubt is, is there any chance of writing a expression int the chart (measure) regarding this.
Thank you
Hi Kiran, you will want to set up a Set Analysis expression, based on a couple of variables (for Max Date and 15 Months Back). There are a couple of Set Analysis examples you could look at here https://www.quickintelligence.co.uk/examples/ – hopefully one of these will help you out.
I guess RAM and SSD Hybrid drives are superbly plentiful on your BI Servers….. Adding 10 data points to 1000 unique dates = 11,0000 data cells (add one field for the linking ID). Adding 10 data points to a million row dataset = 10 MILLION data cells, the vast majority of them redundant……
consider 5 or 10 million row fact tables and this off the charts….. we build our QVD files ahead of time…..and QlikView does a great job in handling the linking overhead in memory of joining the x million facts to the 1 or 4 thousand date dimensions…. Stephen Redmonds is spot on (as always).
Hi Robert – you need to bear in mind that the data is not stored in the same way as a relational database. Duplicate values in a RDBMS would be disastrous for a databases size. In QlikView this is minimized. Stephen is indeed correct that there is an overhead to the pointers in memory size. Pulling data into fewer tables will speed things up as the associations do not need to be done at display time. If you need to conserve memory then splitting into relational tables may be something you consider (after a number of other optimisations) but if you want to conserve CPU and speed things up fewer tables may be better. If neither is a major concern, then few tables may be a simpler data design for people to work with.
You takes your choice.
Hi Steve, another good blog!
I’m just considering best way to use dates in my app. I have a table (Work Requests) which has a number of date fields within, Date Requested, Date Completed, Date Engineer Assigned, Date Overdue etc.
My users will want to be able to make a selection, for example based on month and/or year and see all the values attributed to each of the date fields. So if they selected Month = “December” and Year = “2014”, they would see something (such as counts, or in charts) of all work orders opened, completed & went overdue for that month.
Obvioulsy I need some form of master calendar that user selections are based on and that then pull in / link to the relevant data from the various date fields I have.
I was thinking I may need to set up each of the date fields into separate QVDs (with work request id to link back to the main work requests table/QVD), and a master calendar QVD linking to each of the date QVDs. (hope that makes sense…!).
Is this the right sort of approach in this scenario, and do have have pointers etc you can guide me too?
Regards
Dan
I would suggest an Events table linking to the Work Order table. This would need the ID, Date and Event Type in it. This could be created by loading from the main Work Order table many times, concatenating into the Events. As per the post, I would put the various date breakdowns in that table too.
Hope that helps.
[…] Why You Should Ditch Your QlikView Calendar Script – – Everyone has their way of creating a QlikView calendar script. Here, however, I argue you should ditch that script and do something different…. […]